AI

ChatGPTの学習データ量から、今のChatGPTの現状などを考察してみようという記事です。まだ突っ込み所満載なのですが、お暇ならお付き合いください。
1.ChatGPTの学習データ
ChatGPTの学習データは、インターネット上に公開されている大量のテキストデータを使用していると言われます。具体的な例として、Wikipediaやウェブページ、書籍、ニュース記事、雑誌、論文などの公開されているデジタル化されたテキストテータになります。

ChatGPTの学習データ量
そのテキストデータ量は、GPT-3.5で45TB、それ以降は非公開となっています。
45TBというのは、45,000,000,000,000Bという膨大な量です。
また、GPT-3.5は1750億のパラメータを持つ公開当時は最大のモデルとしても知られています。現在はGPT-4も有料で公開されていますが、そちらはさらに多くのパラメーターを持っていることでしょう。(パラメーター数は非公開)
一方で、この数字は1TBのハードディスク45台分ともいえます。これを多いとみるか、少ないとみるかは意見の分かれる所でしょう。
さて、収集したデータの内容からも見てみましょう。
たとえば、Wikipediaの全記事のファイルサイズは英語版で95GB、日本語版で20GBです。このデータがすべて学習データとなっていることが想像されます。Wikipediaのデータって意外と?少ない。
そして、Common Crawlデータとは、Webサイトなどで公開されているホームページを巡回(クロール)して得たサイトの基本データのことです。現在世界には約19億サイトが存在していますが、その内有効なサイトは25%程度と言われており、約5億サイトになります。そのうちの何割かのデーターを利用しているようです。データ量では9TBだそうです。こちらも9TBを5億サイトで割ると1サイト辺りでは18KBのテキストデータです。日本語だと、9,000文字に相当します。テキストだけだとこんな分量なのかもしれません。
これらの他に独自のデータなどを加えた45TBのデータとなります。
世界の公開データ量と比べる
一方で、こうしたChatGPTの学習データ量を、世界の公開データ量から比較してみます。
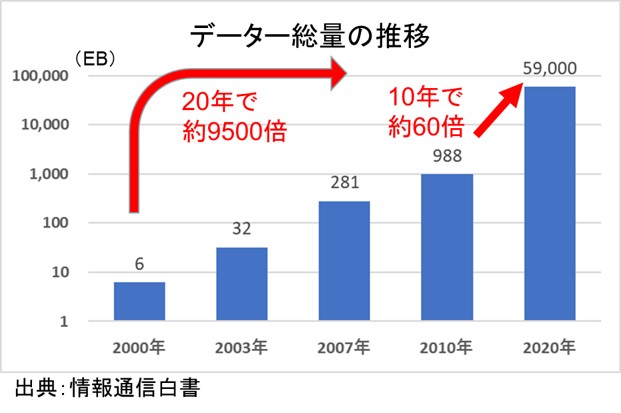
公開データは、総務省が出している情報通信白書に2020年のデータ総量が乗っていました。59ZBとなっています。ちなみにChatGPT3.5は2021年9月までのデータを利用していると言われるので、世界のデータ量も増えていると思いますが、その点は今回は無視することにしました。2021年のデータが見つかったら訂正します。
いずれにしろ、世界のデータ量は、2010年の988EBから10年で59ZBと、60倍になっているほどの急速な拡大をしていることには驚きました。
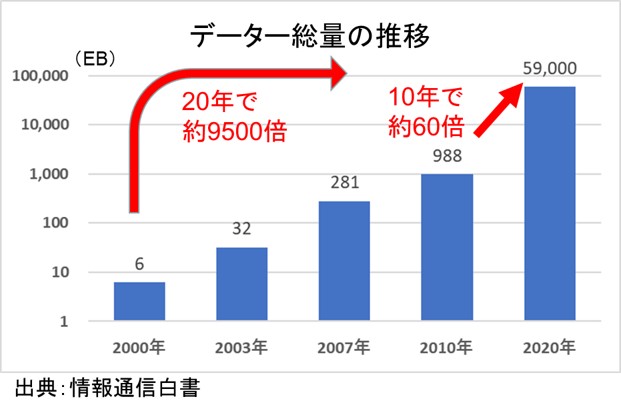
この59ZB(ゼタバイト)という見慣れない単位を、一応確認しておきますね。

私たちがよく目にする1TBハードディスクの10億倍です(;゜ロ゜)
この数値59ZBとGPT3.5のデータ45TBと比べると、

ChatGPTの学習データ量は、世界の公開データの、0.000000076%となります。
この学習データ量からすると、ChatGPT3.5の回答で時々「情報を持っていない」という返答があるのもなんとなく納得できます。
一方でGPT4は、医師国家試験を合格するレベルまで精度が向上しているといわれるので、データ量は未公開ですが、相当程度に強化されているのでしょう。データ量も教えて欲しいです。どなたかご存じありませんか?
2.形式知と暗黙知から
さて、データー量の他に、ChatGPTの限界を考える上で、知の内容も俯瞰しておくのが良さそうです。
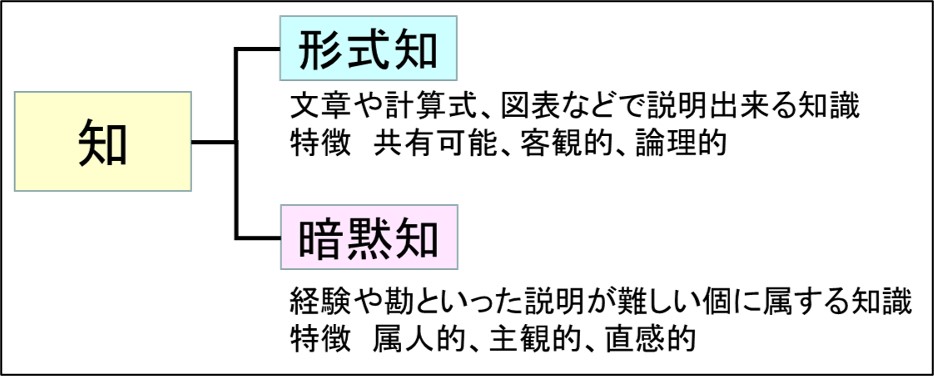
形式知は、文章や計算式、図表などで説明出来る知識です。特徴として、共有可能、客観的、論理的であると言われます。
一方で、暗黙知は、経験や勘といった説明が難しい個に属する知識で、特徴として、 属人的、主観的、直感的と言われます。
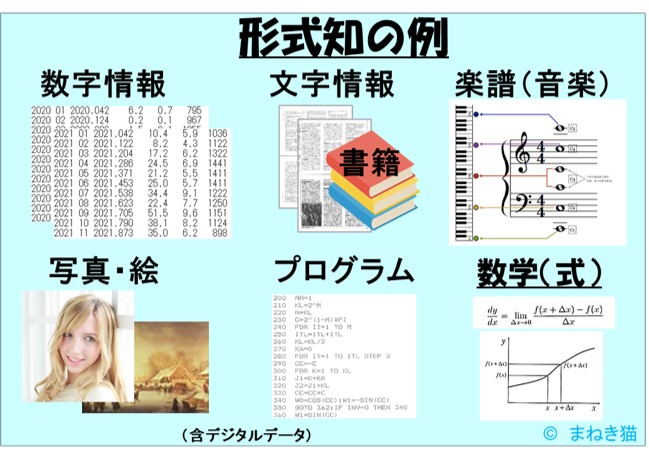
形式知の例を図で示すとこんな感じです。
暗黙知の例はこんな内容です。

こうした知の内容を全体像としてイメージにまとめたのがこちらです。
さきほど世の中の形式知は59ZBというのは、この左側の一部になります。
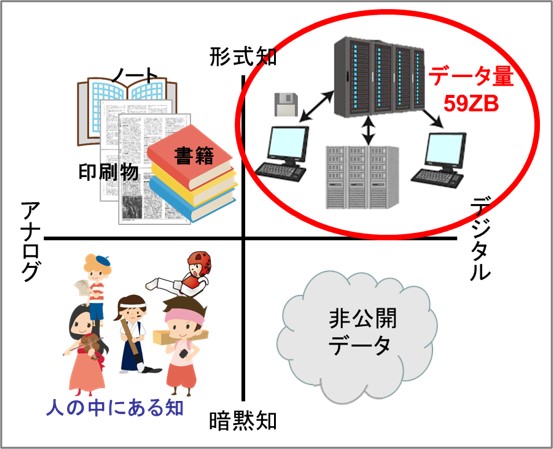
世界のデータ内訳を推定する
ここでフェルミ推定を使って、世の中のデジタルデータの全量を「いえやっ」と推定してみました。

形式知は全体の10%
情報は、暗黙知である一次情報をだれかが加工して二次情報にし、それを公開した三次情報となります。氷山モデルでは、公開される形式知は10%程度と言われています。
暗黙知が90%を占めます。
また、形式知の約33%が事実や法則情報で、66%が推論や意見と分析されています。この前提から公開されている形式知の内容を計算すると、以下のようになります。

こうした前提から、公開データが59ZBの内、事実などは20ZBで、推論や意見などが39ZBと思われます。
公開データの66%は推測や意見という点は考えさせられます。こうした点も、ChatGPTの回答に「あれっ」と思う原因があるように思います。AIはデータの正誤は一部しか反映していません(教師付データのみ)こうした点も回答に影響があると推察できます。
そして非公開データは、531ZBと推定しました。
合計すると世の中のデジタルデータの総量は、590ZBと推定されます。
一方、この他にアナログの情報や、人の中に内在する経験などの暗黙知も存在しています。この部分はどのくらいあるかを今の所推定できません。
このように世の中のデータ量が膨大だということは、確認できました。その点からするとChatGPTもまだ学ぶことが多いですね。また。教師付データや正誤判定データの生成は、生成AIを研究されている方の大きな課題となっていることでしょう。
3.形式知でAIが利用可能なデータ量
さきほど2020年のデータ総量が59ZBと示しましたが、そのデータ内訳も確認してみましょう。
色々調べましたが、内訳をきちんと説明している資料が見当たりませんでした。
しかたがないので、トラヒック量から推定します。

こちらも総務省の令和2年版(2020年)の情報通信白書にあったデータです。
世界データの61%は画像データ?
トラヒックデータの61%が動画配信だそうです。Webは、13%といった状況です。
圧倒的に動画データが多いですね。
こうした点から、生成系AIの得意領域は画像だということも推定できます。
学ぶデータが多いほど生成系AIは賢くなっていくことでしょう。
また、先ほど求めたChatGPTの学習データのテキストデータの利用率は、テキストデータが少ない分修正する必要がありそうです。たぶんですが、全データの約10%がテキストデータと仮定すると、
さきほど求めた、
0.000000076%が
0.00000076%と
1桁改善する程度ですが(;゜ロ゜)
4.おわりに
ChatGPTの学習データは45TBでした。
世界の全データ量59ZBの10%とすると、約0.00000076%のデータを利用していると推定しました。ChatGPTが学ぶ点がまだ多い状況です。
また、形式知データの66%は、推測と意見です。こうしたデータの扱いをどうするかも課題でしょう。
一方、データ流通量からすると、画像生成系AIに利用できるデータが多いので、この点での進歩はかなり早いと推察されます。
また、暗黙知がデータ量で、公開データの約9倍531ZBがあると推定できるので、こうした知の活用で、AIが利用出来ない領域として残ることになります。もちろん、生成系AIも進歩しますので、油断は出来ません。
現状の誤回答の多さや、試験問題やプログラミングなどで良い結果を出している点が、だいたい理解できそうです。
今後の進歩も観察しながら、自身の活躍の場を考えて行くことが重要では無いかと思いました。
まだまだデータや考察が足りない点が多々あるので、今後も考察を深めてみたいと思います。また、機会があったら更新してみます。

最後まで読んでいただきありがとうございました。

こうした記事も読んでやってください。
![]()
終わり
